

개인정보보호정책
Frameout은 이용자의 개인정보를 소중히 여기며, 개인정보 보호법 등 관련 법령을 준수합니다. 수집된 개인정보는 서비스 제공 및 상담, 제안서 접수 등 정해진 목적 외에는 사용되지않습니다. 또한, 이용자의 동의 없이는 개인정보를 외부에 제공하지 않습니다.
개인정보 수집 및 이용 동의
Frameout은 입사지원 및 제안 요청/상담을 위해 이름, 연락처, 이메일 주소 등의 정보를 수집합니다. 수집된 정보는 입사지원 및 채용전형 진행, 입사지원정보 검증을 위한 제반 절차 수행과 제안서 작성, 상담 응대 등 업무 처리 목적에 한해 이용됩니다. 해당 정보는 제3자에게 제공하거나 입사 진행 절차 이외에는 사용하지 않습니다. 이용자는 개인정보 제공에 동의하지 않을 수 있으며, 미동의 시 일부 서비스 이용이 제한될 수 있습니다.
개인정보 보유 및 이용기간
수집된 개인정보는 수집 목적 달성 후 즉시 파기되며, 보관이 필요한 경우 관련 법령에 따라 일정 기간 보관됩니다. 기본 보유 기간은 1년이며, 이후에는 지체 없이 안전하게 삭제됩니다. 이용자는 언제든지 개인정보 삭제 요청이 가능합니다.

온디바이스 AI는 매력적인 약속을 갖고 있습니다.
빠릅니다.
개인정보를 보호할 수 있습니다.
네트워크가 없어도 작동할 수 있습니다.
사용량이 늘어도 서버 비용이 폭증하지 않습니다.
하지만 모바일 온디바이스 AI는 동시에 매우 냉정한 제약을 갖고 있습니다.
메모리는 작고, 배터리는 제한적이며, 모델 크기는 줄여야 하고, iOS와 Android의 동작 조건은 다릅니다.
클라우드처럼 거대한 모델을 계속 서버에서 바꾸며 개선할 수도 없습니다.
앱에 들어간 모델이 사용자 기기에 내려가는 순간, 그 품질은 곧 제품의 신뢰가 됩니다.
Arduskey 공식 사이트: http://www.arduskey.com
Arduskey 개발에서 프레임아웃이 마주한 가장 큰 질문은 이것이었습니다.
“모바일 기기 안에서만 돌아가는 AI가, 실제 사용자가 매일 쓸 수 있는 수준의 한국어 음성 입력 경험을 만들 수 있는가?”
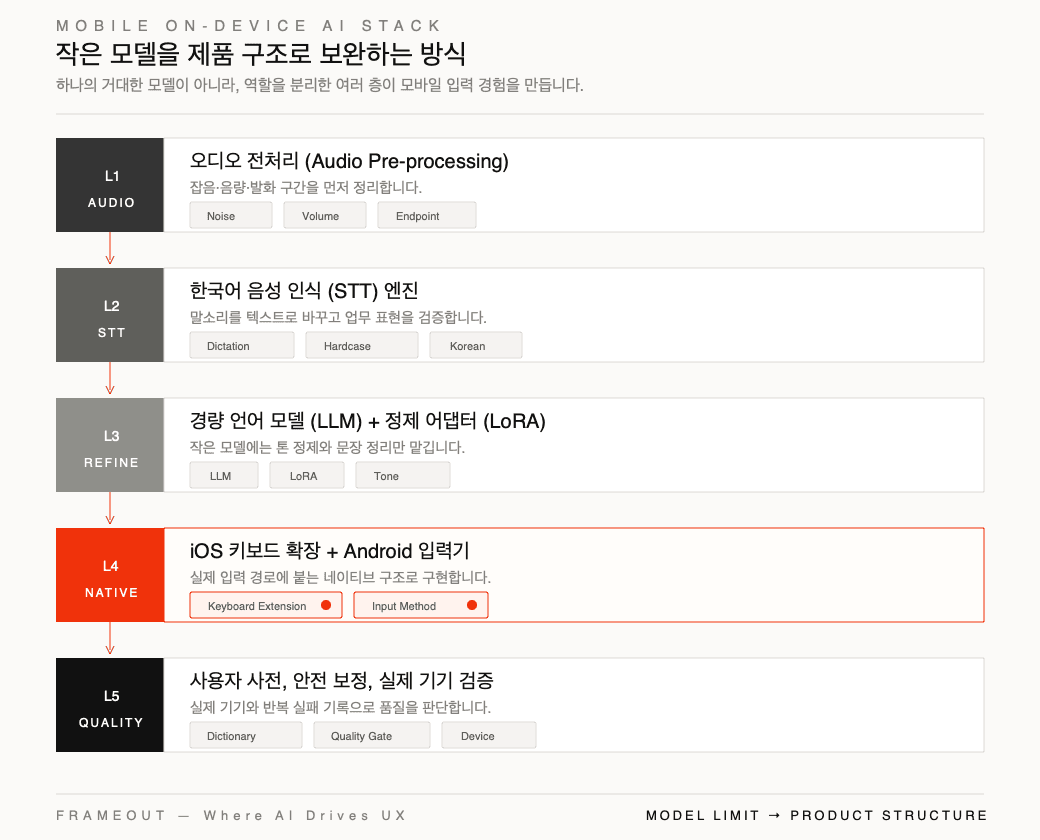
Arduskey의 기술 스택
Arduskey는 하나의 거대한 모델이 모든 것을 해결하는 구조가 아닙니다.
모바일 제약을 고려해 여러 층을 나누고, 각 층이 맡아야 할 일을 분리했습니다.
핵심 구조는 다음과 같습니다.
- 한국어 음성 인식 (STT) 엔진
- 기기 안에서 실행되는 경량 언어 모델 (LLM)
- 상황별 톤 정제를 위한 어댑터 구조 (LoRA)
- iOS 키보드 확장 (Keyboard Extension)과 Android 입력기 (Input Method) 중심의 네이티브 앱 구조
- 잡음, 음량, 발화 구간을 다루는 오디오 전처리 (Audio Pre-processing) 파이프라인
- 사용자 사전 (User Dictionary)과 안전한 문맥 보정 규칙
- 실제 기기 검증과 오류 기록을 기반으로 한 품질 관리 체계 (Quality Gate)
이 구조에서 중요한 것은 “모델이 작다”가 아닙니다.
“작은 모델에게 무엇을 시키고, 무엇을 시키지 않을 것인가”입니다.
클라우드 대형 언어 모델 (LLM)이 잘하는 복잡한 다단계 추론이나 실시간 지식 검색은 음성 입력의 핵심 요구가 아닙니다.
반대로 사용자가 실제로 원하는 것은 정확한 음성 인식, 자연스러운 한국어 정리, 개인정보 보호, 배터리 효율, 저렴한 가격, 전문 분야 확장성입니다.
Arduskey는 이 기준에 맞춰 기술 스택을 설계했습니다.
첫 번째 벽: 작은 모델의 품질 한계
모바일에서 0.5B 또는 1.5B 모델을 사용하는 것은 현실적인 선택입니다.
하지만 작은 모델은 클라우드 대형 모델처럼 모든 문맥을 완벽히 추론할 수 없습니다.
그래서 Arduskey는 작은 모델을 “만능 두뇌”로 쓰지 않습니다.
음성 인식은 음성 인식 (STT) 엔진이 맡습니다.
톤 정제는 정제 어댑터 (LoRA)가 맡습니다.
전문 분야 어휘는 사용자 사전 (User Dictionary)과 분야별 정제 어댑터 (Vertical LoRA)가 맡습니다.
좁은 반복 오류는 규칙 기반 보정층 (Deterministic Repair Layer)이 맡습니다.
위험한 자동 변환은 품질 검증 기준 (Quality Gate)을 통과하기 전까지 기본값으로 켜지 않습니다.
이렇게 역할을 나누면 작은 모델의 한계를 제품 구조로 흡수할 수 있습니다.
두 번째 벽: 한국어 음성 인식의 정체 구간
한국어 음성 인식에서 어려운 부분은 단순히 “단어를 더 많이 학습하면 된다”로 해결되지 않습니다.
업무 문장에는 한자어와 숫자, 외래어, 파일명, 일정 표현, 금액 표현이 섞입니다.
예를 들어 제안서, 견적서, 납품, 위약금, 지급 기한, 파일 전송, 일정 지연 같은 표현은 실제 업무 음성 입력에서 자주 나오지만, 음소가 비슷하거나 문맥이 좁으면 쉽게 흔들립니다.
초기 테스트에서 프레임아웃은 중요한 사실을 확인했습니다.
일반 한국어 발화는 빠르게 안정화될 수 있었습니다.
실제 기기 사용 검증에서는 짧은 일반 발화가 안정적으로 들어오고, 처리 속도도 모바일 사용에 적합한 범위에 들어왔습니다.
하지만 어려운 업무 표현은 다른 문제였습니다.
학습 반복 횟수를 늘리거나 특정 문장을 더 넣는 것만으로는 정체 구간이 쉽게 깨지지 않았습니다.
오히려 특정 영역을 더 세게 학습시키면 일반 발화나 숫자 표현이 퇴화할 위험이 생겼습니다.
이때 프레임아웃은 방향을 바꿨습니다.
“더 많이 학습하자”가 아니라,
“어느 층에서 실패했는지 먼저 분해하자.”
근거 우선: 좋아 보인다는 말로는 출시하지 않는다
Arduskey의 음성 인식과 문장 정제 의사결정에는 근거 우선 원칙이 적용됩니다.
문자 오류율 (CER)이나 단어 오류율 (WER) 같은 평균 지표 하나가 좋아졌다고 바로 출시 후보가 되지는 않습니다.
전체 정확도, 표현 유형별 정확도, 실제 기기 결과, 반복 실패 기록, 배터리와 속도, 데이터 출처와 라이선스까지 함께 확인해야 합니다.
판단 표현도 네 가지로 제한했습니다.
충분히 확인됨 (Confirmed).
가능성이 있음 (Promising).
현재는 막혀 있음 (Blocked).
채택하지 않음 (Rejected).
“좋아 보인다”는 출시 판단이 아닙니다.
이 기준 때문에 일부 후보는 과감히 멈췄습니다.
테스트는 성공처럼 보였지만, 어려운 표현의 핵심 단어와 의미가 충분히 개선되지 않거나, 문장 정제 과정에서 화자의 의도가 바뀌는 문제가 발견되면 기본 기능으로 올리지 않았습니다.
이것은 속도를 늦추는 결정처럼 보일 수 있습니다.
하지만 온디바이스 AI 제품에서는 품질이 한번 사용자 기기에 내려간 뒤 신뢰를 잃으면 회복이 어렵습니다.
프레임아웃은 빠른 출시보다 신뢰 가능한 첫 경험을 우선합니다.
정체 구간을 넘기 위한 9개 축
프레임아웃은 음성 인식 문제를 하나의 학습 반복으로 보지 않습니다.
현재 Arduskey의 음성 인식 품질 개선은 9개 축으로 분해되어 있습니다.
- 데이터 출처와 무결성
- 자연 발화와 업무 표현의 학습 비율
- 특정 표현을 고치면서 일반 발화가 나빠지지 않게 하는 보호 장치
- 반복 실패 표현의 기록과 재검증
- 비슷한 소리와 발음 혼동 분석
- 음성 인식 결과가 연쇄적으로 무너지는 구간 분석
- 개발 환경과 실제 기기 결과의 차이 확인
- 사용자 사전, 문맥 보정, UX 보완
- 잡음, 음량, 발화 시작과 끝을 다루는 오디오 처리
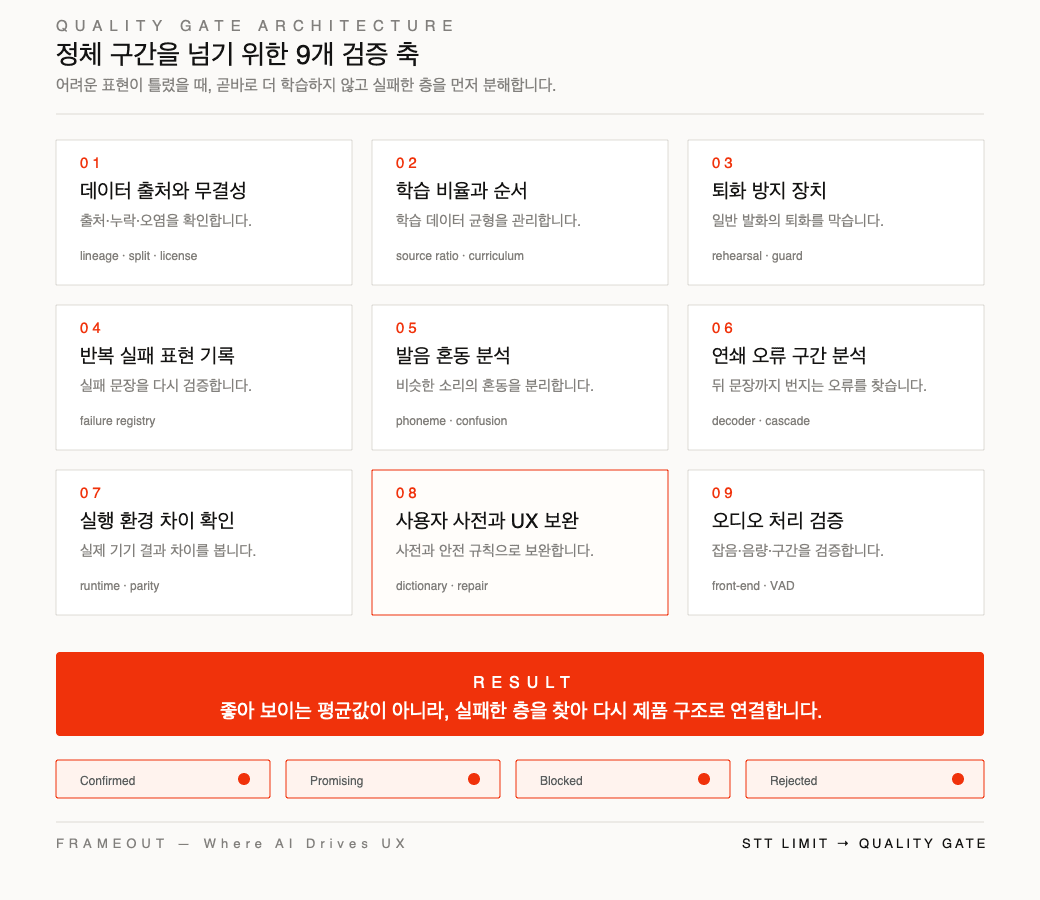
이 9개 축은 제품 개발팀의 체크리스트가 아니라, AI 제품을 출시 가능한 수준으로 끌어올리기 위한 운영 방식입니다.
예를 들어 어떤 표현이 틀렸을 때 곧바로 “학습을 더 하자”로 가지 않습니다.
실제 음성 데이터에 그 표현이 충분히 있었는지 봅니다.
비슷한 발음이 섞인 문제인지 봅니다.
음성 인식 과정에서 오류가 연쇄적으로 커진 문제인지 봅니다.
개발 환경과 실제 기기에서 결과가 달라지는지 봅니다.
사용자 사전이나 문맥 보정으로 안전하게 해결 가능한지 봅니다.
일반 발화가 함께 나빠지지 않는지 봅니다.
이 분해 덕분에 테스트는 더 느리지만 더 정확해졌습니다.
제품화에 가까워진 부분과 아직 남아 있는 부분
Arduskey는 이미 여러 층에서 제품화 기반을 갖추고 있습니다.
iOS 앱과 키보드 extension은 native 구조로 구현되어 있습니다.
음성 인식 엔진은 실제 기기 사용 검증을 통해 속도와 기본 동작을 확인하고 있습니다.
한국어 일반 발화는 유의미한 안정성을 보이고 있습니다.
어려운 업무 표현은 실패 기록과 추가 검증 문장으로 분리되어, 어떤 실패를 어떤 층에서 해결해야 하는지 명확해지고 있습니다.
문장 정제 모델과 기본 모델 자산은 보존되어 있으며, 기본 기능으로 활성화하기 전에는 별도의 문장 검증과 실제 기기 검증을 다시 거쳐야 합니다.
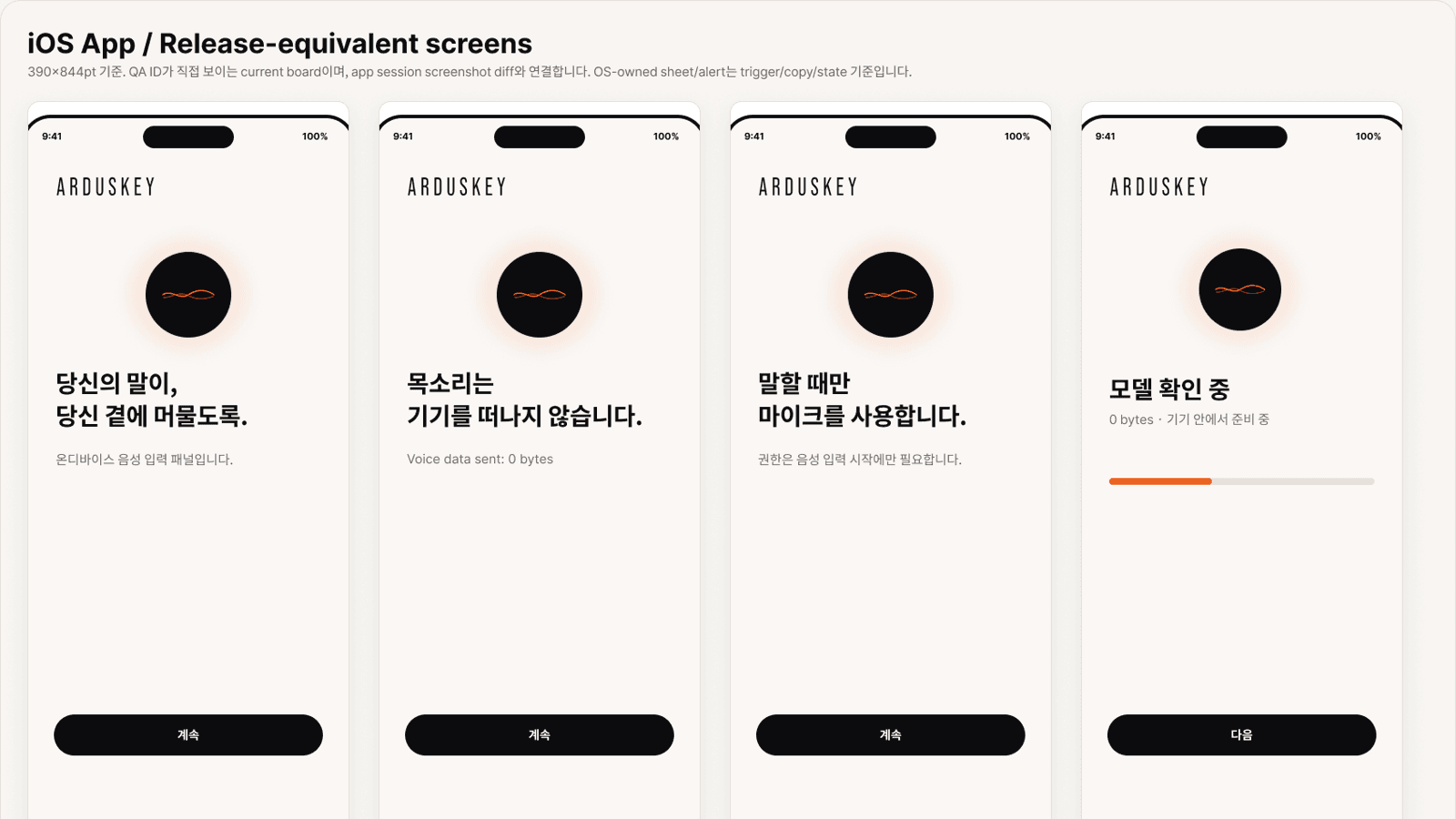
중요한 것은, 남아 있는 부분을 회피하지 않고 반드시 끝까지 풀어낼 구조를 만들고 있다는 점입니다.
업무 표현 일부는 여전히 정체 구간으로 남아 있습니다.
정제 모델은 엔티티와 화자 의도를 보존해야 합니다.
모델 다운로드, 파일 무결성 검증, iOS와 Android의 실제 기기 결과 일치성, 더 넓은 사용자 상황 검증도 계속 남아 있습니다.
이것은 약점이 아니라 AI 제품 개발의 현실입니다.
AI native company는 실패가 없다고 말하는 회사가 아닙니다.
실패를 측정하고, 분류하고, 다음 개선으로 연결하는 회사를 말합니다.
Arduskey의 기술 스택은 단순한 모델 조합이 아닙니다.
모바일 온디바이스 AI의 한계를 제품화 가능한 수준으로 다루기 위한 검증 체계입니다.
프레임아웃은 이 체계를 통해 AI driven UX를 구호가 아니라 실제 제품 개발 방법론으로 만들고 있습니다.
Where AI Drives UX, FRAMEOUT